Influx DB & IoT Service
DON'T WAIT ANY LONGER
F.A.Q
1. 시계열 DB인 인플럭스 DB가 무엇인가요?
InfluxDB는 오픈 소스 시계열 데이터베이스로서, 대량의 시간에 따라 변화하는 데이터를 저장하고 검색하기 위한 목적으로 설계된 데이터베이스 시스템입니다. 주로 센서 데이터, 메트릭 데이터, 이벤트 데이터 등의 시계열 데이터를 처리하고 분석하는 데 사용됩니다.
InfluxDB는 시계열 데이터에 특화된 구조와 기능을 제공하여 데이터의 효율적인 저장, 쿼리, 집계 및 시각화를 가능하게 합니다. 다양한 분야에서 사용되며, 모니터링, IoT (Internet of Things), 로그 분석, 애플리케이션 성능 관리 등 다양한 시나리오에서 활용될 수 있습니다.
InfluxDB는 다음과 같은 주요 특징을 가지고 있습니다
InfluxDB는 시계열 데이터에 특화된 구조와 기능을 제공하여 데이터의 효율적인 저장, 쿼리, 집계 및 시각화를 가능하게 합니다. 다양한 분야에서 사용되며, 모니터링, IoT (Internet of Things), 로그 분석, 애플리케이션 성능 관리 등 다양한 시나리오에서 활용될 수 있습니다.
InfluxDB는 다음과 같은 주요 특징을 가지고 있습니다
- 시계열 데이터 저장: InfluxDB는 대용량의 시계열 데이터를 효율적으로 저장하기 위해 설계되었습니다. 데이터는 "measurement"과 "tag"로 구성되며, 태그는 데이터를 탐색하고 필터링하는 데 사용됩니다.
- 쿼리와 집계: InfluxDB는 SQL에 유사한 쿼리 언어인 InfluxQL과 Flux를 지원하여 데이터를 조회하고 필터링할 수 있습니다. 집계 기능을 통해 데이터의 통계 정보를 계산할 수도 있습니다.
- 연속적인 쿼리: InfluxDB는 데이터의 연속적인 쿼리를 지원하여 지정된 시간 범위 내에서 데이터를 실시간으로 조회할 수 있습니다.
- 데이터 보존 정책: InfluxDB는 데이터 보존 정책을 설정하여 시간에 따라 데이터를 자동으로 삭제하거나 보관할 수 있습니다.
- 확장성: InfluxDB는 수평적으로 확장 가능한 아키텍처를 가지고 있어 대규모 데이터 처리에 유리합니다.
- 데이터 입력 및 출력: InfluxDB는 다양한 데이터 입력 및 출력 방법을 지원합니다. 데이터를 직접 쓰고 읽을 수 있는 API, 클라이언트 라이브러리, Telegraf와 같은 데이터 수집기, 여러 시각화 도구 등을 활용할 수 있습니다.
2. 인플럭스DB에서 사용하는 용어

3. InfluxDB Enterise와 OSS의 차이점은 무엇인가요?
InfluxDB Enterprise와 InfluxDB OSS (Open Source Software) 사이에는 몇 가지 중요한 차이점이 있습니다.
- 라이선스: InfluxDB Enterprise는 상용 라이선스를 사용하는 상용 제품이며, InfluxDB OSS는 오픈 소스 라이선스인 MIT 라이선스를 따르는 오픈 소스 프로젝트입니다. 상용 라이선스를 사용하는 InfluxDB Enterprise는 추가적인 기능과 기업 환경에서의 지원을 제공합니다.
- 기능: InfluxDB Enterprise는 고급 기능을 포함하고 있어 기업 환경에서 요구되는 기능을 제공합니다. 예를 들어, 엔터프라이즈 버전은 클러스터링, 데이터 복제, 백업 및 복원 등의 기능을 제공합니다. 반면, InfluxDB OSS는 기본적인 시계열 데이터베이스 기능을 제공합니다.
- 지원: InfluxDB Enterprise는 기업 환경에서의 요구에 맞는 기술 지원을 제공합니다. 이는 문제 해결, 성능 튜닝, 업그레이드 지원 등을 포함할 수 있습니다. InfluxDB OSS의 경우, 커뮤니티 지원에 의존해야 하며, 오픈 소스 커뮤니티에서 지원을 받을 수 있습니다.
- 확장성: InfluxDB Enterprise는 고가용성 및 확장성을 위한 클러스터링 기능을 제공합니다. 이를 통해 대규모 데이터 처리 및 고가용성 요구 사항을 충족할 수 있습니다. InfluxDB OSS는 단일 인스턴스로 사용되기 때문에 확장성 측면에서는 제한적입니다.
- 비용: InfluxDB Enterprise는 상용 제품이므로 사용에 따라 라이선스 비용이 발생합니다. 비용은 기업의 요구 사항, 라이선스 모델 및 지원 수준에 따라 다를 수 있습니다. InfluxDB OSS는 오픈 소스로 제공되며 무료로 사용할 수 있습니다.
4. 인플럭스 DB는 이런 분야에서 꼭 사용해야합니다.
InfluxDB는 다양한 분야에서 사용될 수 있으며, 특히 아래와 같은 경우에 꼭 사용할 수 있습니다
- 모니터링 및 애플리케이션 성능 관리: InfluxDB는 성능 지표, 로그 데이터, 이벤트 데이터 등의 실시간 데이터를 수집하고 저장하기에 적합합니다. 애플리케이션의 성능 모니터링, 서버 모니터링, 네트워크 모니터링 등에서 활용할 수 있습니다.
- IoT (Internet of Things): InfluxDB는 대량의 센서 데이터를 처리하고 저장하는 데 사용됩니다. 센서 데이터는 시간에 따라 변화하며, 이러한 데이터를 실시간으로 수집하고 분석하는 IoT 애플리케이션에서 많이 사용됩니다.
- 로그 분석: InfluxDB는 로그 데이터를 저장하고 분석하는 데에도 사용됩니다. 로그 데이터는 시간 정보가 중요하며, InfluxDB를 활용하여 로그 데이터를 저장하고 쿼리하여 문제 해결이나 분석에 활용할 수 있습니다.
- 이벤트 기반 아키텍처: InfluxDB는 이벤트 기반 아키텍처에서 중요한 역할을 수행할 수 있습니다. 이벤트 기반 시스템에서 발생하는 이벤트 데이터를 수집하고 저장하여 실시간으로 분석하고 응답할 수 있습니다.
- 금융 및 주식 시장: 시계열 데이터는 금융 및 주식 시장에서 중요한 역할을 합니다. InfluxDB를 활용하여 주식 가격, 거래 데이터, 금융 지표 등의 데이터를 저장하고 분석할 수 있습니다.
- 에너지 모니터링: 에너지 소비 데이터는 시계열 형태로 수집되며, InfluxDB를 사용하여 에너지 사용량을 저장하고 분석하여 에너지 효율성을 향상시킬 수 있습니다.
5. InfluxDB Enterise의 사이징(Spec)은 어떻게합니까?
InfluxDB Enterprise의 사이징은 여러 가지 요인에 따라 다를 수 있습니다. 다음은 일반적으로 고려해야 할 사항입니다
- 데이터 양: InfluxDB Enterprise의 사이징은 저장하고자 하는 데이터의 양에 따라 결정됩니다. 데이터의 크기, 빈도 및 보존 기간에 따라 필요한 디스크 공간과 메모리 용량을 고려해야 합니다.
- 쓰기 및 읽기 요청량: InfluxDB Enterprise의 성능은 동시에 처리해야 하는 쓰기 및 읽기 요청의 양과 속도에 영향을 받습니다. 쓰기 요청의 처리량, 응답 시간 및 읽기 요청의 처리량에 대한 요구 사항을 고려하여 리소스를 할당해야 합니다.
- 고가용성 및 확장성 요구 사항: InfluxDB Enterprise는 고가용성을 제공하고 수평적으로 확장 가능한 클러스터 구성을 지원합니다. 클러스터의 규모, 고가용성 요구 사항, 데이터 복제 및 분산 처리를 고려하여 사이징을 결정해야 합니다.
- 하드웨어 사양: InfluxDB Enterprise는 하드웨어 리소스에 따라 성능이 달라집니다. CPU, 메모리, 디스크 I/O 등의 하드웨어 사양을 고려하여 최적의 성능을 달성할 수 있는 사이징을 수행해야 합니다.
- 데이터 유형과 쿼리 복잡도: 데이터의 유형과 쿼리의 복잡도도 사이징에 영향을 줍니다. 데이터의 필드 수, 태그 수, 쿼리의 집계 수준 등을 고려하여 사이징을 수행해야 합니다.
6. 데이타 백업과 복구는 어떻게 합니까?
InfluxDB에서 데이터 백업과 복구는 다음과 같은 방법으로 수행할 수 있습니다
- 백업
- InfluxDB의 데이터를 백업하기 위해서는 데이터베이스의 스냅샷을 생성해야 합니다. 스냅샷은 현재 데이터베이스 상태의 복제본으로, 데이터베이스의 모든 데이터와 구조를 포함합니다.
- InfluxDB에서는 influxd backup 명령어를 사용하여 스냅샷을 생성할 수 있습니다. 이 명령어는 백업 파일을 생성하고 지정된 경로에 저장합니다.
- 주의해야 할 점은 백업 시 데이터베이스가 동작 중이어야 하며, 데이터의 일관성을 유지하기 위해 백업 중에 데이터의 쓰기 작업을 일시 중지해야 할 수도 있습니다.
- 복구
- 백업된 스냅샷 파일을 사용하여 InfluxDB 데이터를 복구할 수 있습니다. 복구 작업을 수행하기 전에는 기존 데이터베이스를 백업하거나 다른 위치에 이동하는 것이 좋습니다.
- influxd restore 명령어를 사용하여 백업된 스냅샷 파일을 복구합니다. 이 명령어는 스냅샷 파일에서 데이터를 읽고 복구된 데이터를 새로운 데이터베이스에 저장합니다.
- 복구 후에는 데이터베이스를 다시 시작하여 새로운 데이터베이스에 액세스할 수 있습니다.
7. 보관주기설정(RP)은 어떻게 하나요?
InfluxDB에서 데이터 보존 정책(Retention Policy, RP)을 설정하는 방법은 다음과 같습니다
RP 적용 후에 적용이 안되는 경우, 체크 사항
1. data node 1 실행
- sudo systemctl restart influxdb.service
2. 1번 완료 후 data node 2 실행
- sudo systemctl restart influxdb.service
3.데이터 볼륨 체크 쿼리 실행
SELECT max("used_percent") FROM "telegraf".."disk" WHERE time > :dashboardTime: AND time < :upperDashboardTime: AND "path" = '/influxdb/data' AND time > :dashboardTime: GROUP BY time(:interval:), "host" fill(null)
4. The table below outlines the default relationship between the DURATION of an RP and the time interval of a shard group:

- RP 생성
- CREATE RETENTION POLICY 문을 사용하여 RP를 생성합니다. 이 때, RP에는 이름, 보존 기간, 기본 RP 여부 등을 지정해야 합니다.
- 예를 들어, 다음 명령어를 사용하여 my_rp라는 이름의 RP를 생성하고, 보존 기간을 30일로 설정할 수 있습니다:sqlCREATE RETENTION POLICY my_rp ON my_database DURATION 30d REPLICATION 1 DEFAULT
- RP 적용
- ALTER DATABASE 문을 사용하여 데이터베이스에 생성한 RP를 적용할 수 있습니다. RP를 적용하면 해당 데이터베이스에 새로운 측정값이 추가될 때 RP에 따라 데이터가 보존됩니다.
- 예를 들어, 다음 명령어를 사용하여 my_rp RP를 my_database 데이터베이스에 적용할 수 있습니다:sqlALTER DATABASE my_database SET RETENTION POLICY my_rp
- 기본 RP 설정
- DEFAULT 키워드를 사용하여 RP를 기본으로 설정할 수 있습니다. 기본 RP는 측정값이 특정 RP에 속하지 않을 경우에 사용되는 RP입니다.
- 예를 들어, 위에서 생성한 my_rp RP를 기본 RP로 설정하려면 다음 명령어를 사용합니다
- RP가 "Autogen"인 경우에는 반드시 마지막에 "DEFAULT"을 꼭 넣어야합니다.
- ALTER RETENTION POLICY my_rp DEFAULT
- RP 조회
- SHOW RETENTION POLICIES 문을 사용하여 데이터베이스에 설정된 RP를 조회할 수 있습니다. 이를 통해 RP의 이름, 보존 기간, 기본 RP 여부 등을 확인할 수 있습니다.
- 예를 들어, 다음 명령어를 사용하여 my_database 데이터베이스의 RP를 조회할 수 있습니다:graphqlSHOW RETENTION POLICIES ON my_database
RP 적용 후에 적용이 안되는 경우, 체크 사항
1. data node 1 실행
- sudo systemctl restart influxdb.service
2. 1번 완료 후 data node 2 실행
- sudo systemctl restart influxdb.service
3.데이터 볼륨 체크 쿼리 실행
SELECT max("used_percent") FROM "telegraf".."disk" WHERE time > :dashboardTime: AND time < :upperDashboardTime: AND "path" = '/influxdb/data' AND time > :dashboardTime: GROUP BY time(:interval:), "host" fill(null)
4. The table below outlines the default relationship between the DURATION of an RP and the time interval of a shard group:
8. 보존 정책을 변경한 후 데이터가 삭제되지 않는 이유는 무엇입니까?
The first and most likely cause is that, by default, InfluxDB checks to enforce an RP every 30 minutes. You may need to wait for the next RP check for InfluxDB to drop data that are outside the RP’s new DURATION setting. The 30 minute interval is configurable.
Second, altering both the DURATION and SHARD DURATION of an RP can result in unexpected data retention. InfluxDB stores data in shard groups which cover a specific RP and time interval. When InfluxDB enforces an RP it drops entire shard groups, not individual data points. InfluxDB cannot divide shard groups.
If the RP’s new DURATION is less than the old SHARD DURATION and InfluxDB is currently writing data to one of the old, longer shard groups, the system is forced to keep all of the data in that shard group. This occurs even if some of the data in that shard group are outside of the new DURATION. InfluxDB will drop that shard group once all of its data is outside the new DURATION. The system will then begin writing data to shard groups that have the new, shorter SHARD DURATION preventing any further unexpected data retention.
Second, altering both the DURATION and SHARD DURATION of an RP can result in unexpected data retention. InfluxDB stores data in shard groups which cover a specific RP and time interval. When InfluxDB enforces an RP it drops entire shard groups, not individual data points. InfluxDB cannot divide shard groups.
If the RP’s new DURATION is less than the old SHARD DURATION and InfluxDB is currently writing data to one of the old, longer shard groups, the system is forced to keep all of the data in that shard group. This occurs even if some of the data in that shard group are outside of the new DURATION. InfluxDB will drop that shard group once all of its data is outside the new DURATION. The system will then begin writing data to shard groups that have the new, shorter SHARD DURATION preventing any further unexpected data retention.
9. 리눅스 시스템에서 vm.max_map_count 값이 너무 낮게 설정되어 있으면 다음과 같은 문제가 발생할 수 있습니다:
- Out of Memory (OOM) 오류: vm.max_map_count는 시스템에서 가상 메모리 맵의 최대 개수를 제어합니다. 가상 메모리 맵은 프로세스가 사용하는 메모리 주소 공간과 파일을 매핑하는 데 사용됩니다. 너무 낮은 vm.max_map_count 값은 많은 맵을 생성할 수 없으므로 메모리 부족으로 인해 Out of Memory 오류가 발생할 수 있습니다.
- Elasticsearch와 같은 분산 데이터베이스의 문제: Elasticsearch는 대량의 데이터를 인덱싱하고 검색하기 위해 가상 메모리 맵을 사용합니다. 충분한 vm.max_map_count 값이 설정되지 않으면 Elasticsearch와 같은 분산 데이터베이스의 성능이 저하될 수 있습니다.
- 네트워크 소켓 생성 문제: 너무 낮은 vm.max_map_count 값은 네트워크 소켓 생성에도 영향을 줄 수 있습니다. 일부 애플리케이션은 많은 수의 네트워크 소켓을 동시에 열어야 할 수 있으며, 이에 대한 가상 메모리 맵이 필요합니다. 적절한 vm.max_map_count 값이 없으면 소켓 생성에 실패할 수 있습니다.
https://docs.influxdata.com/enterprise_influxdb/v1.10/troubleshooting/frequently-asked-questions/#why-is-influxdb-reporting-an-out-of-memory-oom-exception-when-my-system-has-free-memory
1. 설정값 확인
----
#!/bin/bash
# Get the influxd process ID (PID)
PID=$(ps aux | awk '/influxd/ {print $2}')
# Count the number of maps associated with the influxd process count=$(wc -l < /proc/$PID/maps)
echo "Number of maps associated with influxd process: $count"
2. 조치방법
The max_map_count file contains the maximum number of memory map areas a process may have. The default limit is 65536. We recommend increasing this to 262144 (four times the default) by running the following:
----
sudo echo vm.max_map_count=262144 > /etc/sysctl.d/90-vm.max_map_count.conf
10. 인플럭스DB Enterprise 사이징 템플릿(다운로드)
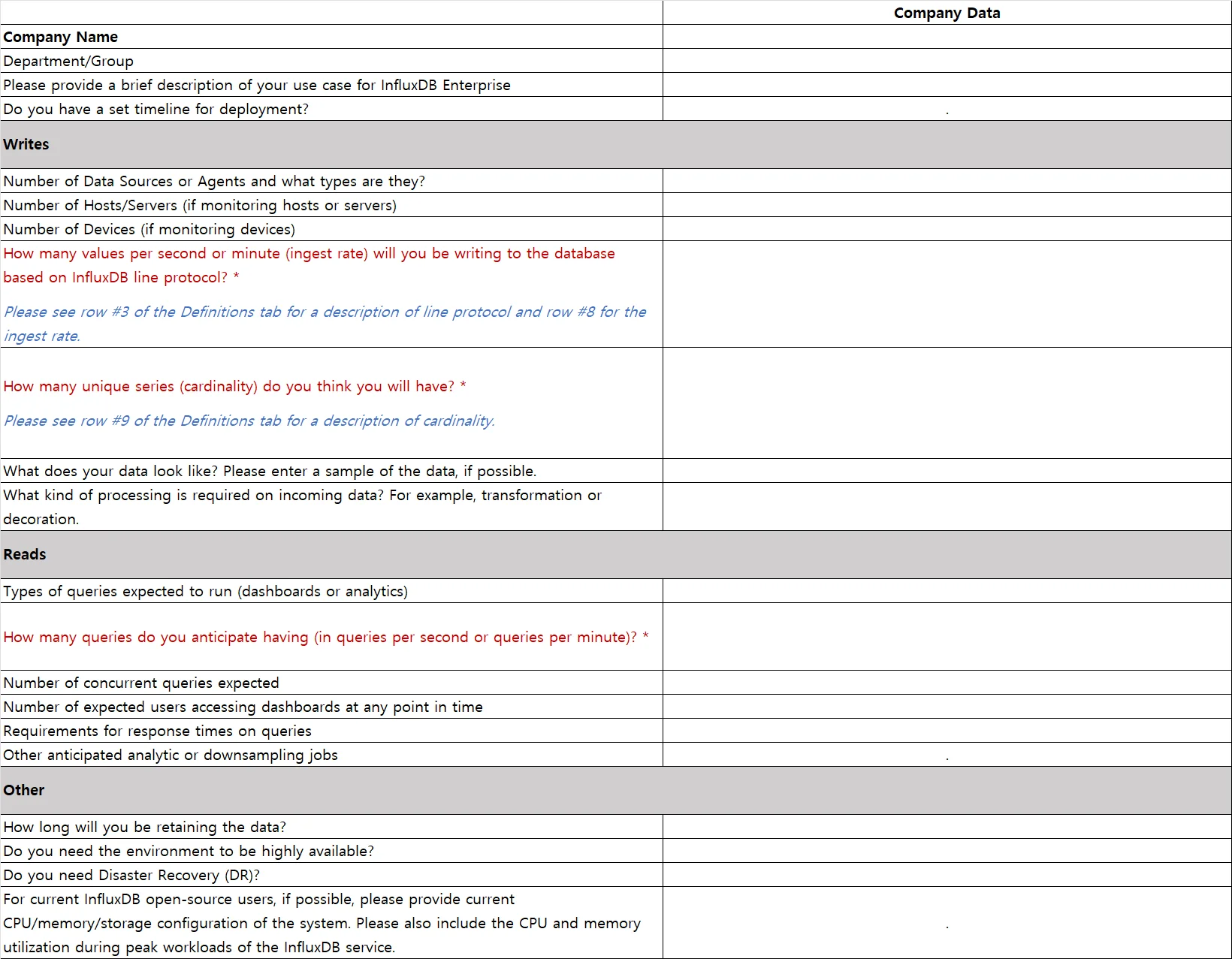
1. Ingest Rate:
SELECT non_negative_derivative(max(""pointsWrittenOK""),1m) FROM ""_internal"".""monitor"".""httpd"" WHERE time > now() - 1h GROUP BY time(1m)"
2. Cardinality:
SHOW SERIES CARDINALITY ON <my_database>
https://docs.influxdata.com/influxdb/v1.8/query_language/spec/#show-series-cardinality"
3. Query volume:
SELECT non_negative_derivative(max(""queriesExecuted""),1m) FROM ""_internal"".""monitor"".""queryExecutor"" WHERE time > now() - 1h GROUP BY time(1m)"
11. Chrongraf 최신 버젼1.10 다운로드 및 설명
https://docs.influxdata.com/chronograf/v1.10/administration/create-high-availability/#Copyright
12. Telegraf 최신 버젼 1.26 다운로드 및 설명
https://docs.influxdata.com/telegraf/v1.26/install/#Copyright
13. error="hinted handoff queue not empty"
예) ** 26 08:30:00 LES*** influxd[8852]: ts=2023-06-25T23:30:00.073940Z lvl=info msg="Remote write failed" log_id=0icU_Mkl000 service=write node_id=5 shard_id=1749 error="hinted handoff queue not empty“
인플럭스DB의 "write shard 1749: short write" 오류는 특정 샤드(Shard)인 1749에서 데이터를 쓸 때 발생한 오류를 나타냅니다. 이 오류는 해당 샤드에 대한 쓰기 작업 중에 일부 데이터만 성공적으로 기록되었거나, 기록되지 않은 상태에서 쓰기 작업이 중단되었음을 의미합니다.
인플럭스DB는 데이터를 분산하여 여러 개의 샤드에 저장하는 분산 데이터베이스 시스템입니다. 각 샤드는 일부 데이터를 담당하고, 쓰기 작업은 해당 샤드에 의해 처리됩니다. "write shard 1749: short write" 오류는 1749번 샤드에서 쓰기 작업 중에 발생한 오류를 가리킵니다.
이 오류의 원인은 여러 가지일 수 있습니다. 몇 가지 가능한 원인은 다음과 같습니다:
인플럭스DB의 "write shard 1749: short write" 오류는 특정 샤드(Shard)인 1749에서 데이터를 쓸 때 발생한 오류를 나타냅니다. 이 오류는 해당 샤드에 대한 쓰기 작업 중에 일부 데이터만 성공적으로 기록되었거나, 기록되지 않은 상태에서 쓰기 작업이 중단되었음을 의미합니다.
인플럭스DB는 데이터를 분산하여 여러 개의 샤드에 저장하는 분산 데이터베이스 시스템입니다. 각 샤드는 일부 데이터를 담당하고, 쓰기 작업은 해당 샤드에 의해 처리됩니다. "write shard 1749: short write" 오류는 1749번 샤드에서 쓰기 작업 중에 발생한 오류를 가리킵니다.
이 오류의 원인은 여러 가지일 수 있습니다. 몇 가지 가능한 원인은 다음과 같습니다:
- 네트워크 문제: 해당 샤드와의 통신 중에 네트워크 연결이 불안정하거나 중단되어 데이터가 일부만 전송되었을 수 있습니다.
- 저장 매체 오류: 1749번 샤드의 저장 매체(예: 디스크)에 문제가 있어 데이터가 제대로 기록되지 않았을 수 있습니다.
- 부하 문제: 쓰기 작업이 해당 샤드에 너무 많아서 일부 데이터를 처리하지 못했을 수 있습니다.
14. Where can I find InfluxDB logs?
On System V operating systems logs are stored under /var/log/influxdb/.
On systemd operating systems you can access the logs using journalctl.
Use journalctl -u influxdb to view the logs in the journal
or
journalctl -u influxdb > influxd.log
to print the logs to a text file. With systemd, log retention depends on your system’s journald settings.
On systemd operating systems you can access the logs using journalctl.
Use journalctl -u influxdb to view the logs in the journal
or
journalctl -u influxdb > influxd.log
to print the logs to a text file. With systemd, log retention depends on your system’s journald settings.
15. PTC Thingworx와 InfluxDB Enterprise와 호환성 버젼
https://support.ptc.com/help/thingworx/platform/r9/en/index.html#page/ThingWorx/Help/Composer/DataStorage/PersistenceProviders/DownloadingAndInstallingInfluxDB1_x.html
1. Choosing the Right Influx Database Option
A high level overview of the two InfluxDB options currently available for PTC on-premise customers follows. The database software options and underlying support options should be carefully considered when choosing an Influx product. For any questions when choosing the correct database options, contact Influx Support: https://www.influxdata.com/contact-sales. PTC customers should identify themselves as PTC ThingWorx users.
2. InfluxDB Enterprise
If you are looking for a data store for higher volumes and velocity data than what is currently available with other databases, then the following benefits are possible with InfluxDB Enterprise:
◦Higher rate of ingestion of data.
◦You can have more than one data repository for run time data. For example, you can keep relational data in PostgreSQL, while using InfluxDB for high volume stream and value stream data. When you define a stream or value stream, ThingWorx uses the default run time data store provider, but you can configure it to use any defined persistence provider. You can still export data from other data providers and import to InfluxDB. ThingWorx handles the data abstraction.
◦Cloud-friendly architecture (horizontal scale, only with InfluxDB Enterprise).
◦High availability available.
◦Influx technical support available with Influx contract using the Influx Support site at InfluxData.
◦PTC customer can open tickets with Influx as needed for PTC/Influx collaboration.
◦PTC customer assumes responsibility for database maintenance and monitoring.
1. Choosing the Right Influx Database Option
A high level overview of the two InfluxDB options currently available for PTC on-premise customers follows. The database software options and underlying support options should be carefully considered when choosing an Influx product. For any questions when choosing the correct database options, contact Influx Support: https://www.influxdata.com/contact-sales. PTC customers should identify themselves as PTC ThingWorx users.
2. InfluxDB Enterprise
If you are looking for a data store for higher volumes and velocity data than what is currently available with other databases, then the following benefits are possible with InfluxDB Enterprise:
◦Higher rate of ingestion of data.
◦You can have more than one data repository for run time data. For example, you can keep relational data in PostgreSQL, while using InfluxDB for high volume stream and value stream data. When you define a stream or value stream, ThingWorx uses the default run time data store provider, but you can configure it to use any defined persistence provider. You can still export data from other data providers and import to InfluxDB. ThingWorx handles the data abstraction.
◦Cloud-friendly architecture (horizontal scale, only with InfluxDB Enterprise).
◦High availability available.
◦Influx technical support available with Influx contract using the Influx Support site at InfluxData.
◦PTC customer can open tickets with Influx as needed for PTC/Influx collaboration.
◦PTC customer assumes responsibility for database maintenance and monitoring.
16. keepalived 를 이용한 haproxy VIP 이중화 로드밸런싱 구성
keepalived + haproxy VIP 이중화 로그밸런싱 구성하기
ㅇ keepalived : VIP 관리, 이중화 구성
ㅇ haproxy : 로드밸런싱
ㅁ 서버 환경
운영환경에서는 web01~02, was01~02를 별도 서버로 구성하지만,
테스트 환경에서는 was서버에 웹서버를 같이 구성합니다.
VIP : 192.168.110.130
ㅁ keepalive 설치
ㅁ keepalive 설정
ㅁ keepalive 시작 및 종료
ㅁ haproxy 설치
ㅁ haproxy 설정
ㅁ haproxy 로그 설정
rsyslog 에 haproxy 용 로그를 남기도록 설정한다. /etc/rsyslog.d/haproxy.conf 파일을 다음과 같이 구성한다.
logroate에 haproxy 설정을 추가한다. /etc/logrotate.d/haproxy 파일을 다음과 같이 구성한다. haproxy 는 재시작할 필요가 없으므로 rsyslog를 재시작해준다.
ㅁ 참고 : https://system-monitoring.readthedocs.io/en/latest/log.html
Status 확인
브라우저로 http://192.168.110.130:81/haproxy.stats 에 접속해보시면 HAProxy의 현재상황을 확인가능합니다.
ㅁ haproxy 시작 및 종료
ㅁ VIP 및 이중화 테스트
ㅁ was01
ㅁ was01 keepalived 중지
[root@was01 keepalived]# systemctl stop keepalived
was01에 140 IP가 failover되어 was02에 올라온다.
ㅁ was02
1. VIP가 올라온 서버의 keepalived가 중지된다면 서비스 정상(failover)
2. VIP가 올라온 서버의 haproxy가 중지된다면 서비스 장애
이유 : VIP는 haproxy01에 올라와 있지만,
haproxy가 죽어서 80포트로 haproxy01:85, haproxy02:85로 httpd 서비스를 로드밸런싱을 할 수 없으므로 장애 발생
ㅁ 서버 커널값 수정
1. HAproxy 가 설치된 서버의 커널 값을 수정합니다. (두 대 모두 수행)
위 부분이 중요한 부분인데, 위 옵션이 뭔지 찾아보면
로컬 IP가 아닌 주소에 bind() 할 수 있게 해줍니다. 라고 되어 있는데요. 말이 어려운데요.
다시 말해서 현재 가지고 있는 IP가 아닌 다른 외부 IP를 NIC에 바인딩 할 수 있게 해준다는 뜻입니다.
이게 왜 중요하냐면 서비스인 VIP를 첫번째 서버가 가지고 있다가 장애가 나는 경우
Standby 서버로 그 VIP를 옮겨야 서비스가 끊기지 않고 돌아갈 수 있기 때문이죠.
저 옵션이 되어 있지 않은 경우 VIP를 바인딩 할 수 없기 때문에 꼭 수정해줘야 합니다.
2. 커널 값 적용 및 확인 (두 대 모두 수행)
위 처럼 1이 나오면 정상적으로 적용됨.
안되는 경우 reboot
출처: https://livegs.tistory.com/44 [if (feel)]
[실무] keepalived.conf 비교
ㅁ 실무 설정 예제
Apache + Tomcat 연동은 아래 게시물을 참고하세요.
Apache2.4 Tomcat8.5 mod_jk 연동 설정 (세션 유지)
https://blog.naver.com/hanajava/221601189158
Keepalived
( 이미지 출처 : access.redhat.com)
https://blog.naver.com/PostView.nhn?isHttpsRedirect=true&blogId=hanajava&logNo=221626055915&categoryNo=40&parentCategoryNo=40&viewDate=¤tPage=1&postListTopCurrentPage=1&from=postList
ㅇ keepalived : VIP 관리, 이중화 구성
ㅇ haproxy : 로드밸런싱
ㅁ 서버 환경
운영환경에서는 web01~02, was01~02를 별도 서버로 구성하지만,
테스트 환경에서는 was서버에 웹서버를 같이 구성합니다.
| HOSTNAME | IP | PORT | DESC |
| VIP | 192.168.110.130 | haproxy01~02 | |
| haproxy01 | 192.168.110.131 | 80 | keepalived+haproxy - Master |
| haproxy02 | 192.168.110.132 | 80 | keepalived+haproxy - Backup |
| web01 (was01) | 192.168.110.141 | 80 | Apache2.4 |
| web02 (was02) | 192.168.110.142 | 80 | Apache2.4 |
| was01 | 192.168.110.141 | 8080 | Tomcat8.5 |
| was02 | 192.168.110.142 | 8080 | Tomcat8.5 |
VIP : 192.168.110.130
| [root@haproxy01 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.110.131 haproxy01 192.168.110.132 haproxy02 [root@haproxy02 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.110.131 haproxy01 192.168.110.132 haproxy02 |
ㅁ keepalive 설치
| [root@haproxy01 ~]# yum install keepalived [root@haproxy02 ~]# yum install keepalived |
| [root@haproxy01 keepalived]# cat keepalived.conf global_defs { notification_email { network-admins@domain.com } notification_email_from web_node1@domain.com smtp_server localhost smtp_connect_timeout 30 router_id WEB_CLUSTER1 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 110 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.110.130 } } [root@haproxy02 keepalived]# cat keepalived.conf global_defs { notification_email { network-admins@domain.com } notification_email_from web_node2@domain.com smtp_server localhost smtp_connect_timeout 30 router_id WEB_CLUSTER1 } vrrp_instance VI_2 { state MASTER interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.110.130 } } |
| [root@haproxy01 keepalived]# systemctl stop keepalived [root@haproxy01 keepalived]# systemctl start keepalived [root@haproxy01 keepalived]# systemctl status keepalived ● keepalived.service - LVS and VRRP High Availability Monitor Loaded: loaded (/usr/lib/systemd/system/keepalived.service; disabled; vendor preset: disabled) Active: active (running) since 금 2019-08-23 16:33:21 KST; 4s ago Process: 29399 ExecStart=/usr/sbin/keepalived $KEEPALIVED_OPTIONS (code=exited, status=0/SUCCESS) Main PID: 29400 (keepalived) CGroup: /system.slice/keepalived.service ├─29400 /usr/sbin/keepalived -D ├─29401 /usr/sbin/keepalived -D └─29402 /usr/sbin/keepalived -D 8월 23 16:33:21 haproxy01 Keepalived_vrrp[29402]: VRRP sockpool: [ifindex(2), proto(112), unicast(0), f...1)] 8월 23 16:33:22 haproxy01 Keepalived_vrrp[29402]: VRRP_Instance(VI_1) Transition to MASTER STATE 8월 23 16:33:23 haproxy01 Keepalived_vrrp[29402]: VRRP_Instance(VI_1) Entering MASTER STATE 8월 23 16:33:23 haproxy01 Keepalived_vrrp[29402]: VRRP_Instance(VI_1) setting protocol VIPs. 8월 23 16:33:23 haproxy01 Keepalived_vrrp[29402]: Sending gratuitous ARP on eth0 for 192.168.110.140 8월 23 16:33:23 haproxy01 Keepalived_vrrp[29402]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs ...140 8월 23 16:33:23 haproxy01 Keepalived_vrrp[29402]: Sending gratuitous ARP on eth0 for 192.168.110.140 |
| [root@haproxy02 keepalived]# systemctl stop keepalived [root@haproxy02 keepalived]# systemctl start keepalived [root@haproxy02 keepalived]# systemctl status keepalived ● keepalived.service - LVS and VRRP High Availability Monitor Loaded: loaded (/usr/lib/systemd/system/keepalived.service; disabled; vendor preset: disabled) Active: active (running) since 금 2019-08-23 16:33:31 KST; 3s ago Process: 3458 ExecStart=/usr/sbin/keepalived $KEEPALIVED_OPTIONS (code=exited, status=0/SUCCESS) Main PID: 3459 (keepalived) CGroup: /system.slice/keepalived.service ├─3459 /usr/sbin/keepalived -D ├─3460 /usr/sbin/keepalived -D └─3461 /usr/sbin/keepalived -D 8월 23 16:33:31 haproxy02 Keepalived_vrrp[3461]: Registering Kernel netlink command channel 8월 23 16:33:31 haproxy02 Keepalived_vrrp[3461]: Registering gratuitous ARP shared channel 8월 23 16:33:31 haproxy02 Keepalived_vrrp[3461]: Opening file '/etc/keepalived/keepalived.conf'. 8월 23 16:33:31 haproxy02 Keepalived_vrrp[3461]: VRRP_Instance(VI_1) removing protocol VIPs. 8월 23 16:33:31 haproxy02 Keepalived_vrrp[3461]: Using LinkWatch kernel netlink reflector... 8월 23 16:33:31 haproxy02 systemd[1]: Started LVS and VRRP High Availability Monitor. 8월 23 16:33:31 haproxy02 Keepalived_vrrp[3461]: VRRP sockpool: [ifindex(2), proto(112), unicast(0), f...1)] 8월 23 16:33:32 haproxy02 Keepalived_vrrp[3461]: VRRP_Instance(VI_1) Transition to MASTER STATE 8월 23 16:33:32 haproxy02 Keepalived_vrrp[3461]: VRRP_Instance(VI_1) Received advert with higher prior...100 8월 23 16:33:32 haproxy02 Keepalived_vrrp[3461]: VRRP_Instance(VI_1) Entering BACKUP STATE |
ㅁ haproxy 설치
| [root@haproxy01 ~]# yum install haproxy [root@haproxy02 ~]# yum install haproxy |
| [root@haproxy01 haproxy]# cat haproxy.cfg #--------------------------------------------------------------------- # Global settings #--------------------------------------------------------------------- global log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 2048 user haproxy group haproxy daemon # turn on stats unix socket stats socket /var/lib/haproxy/stats #--------------------------------------------------------------------- # common defaults that all the 'listen' and 'backend' sections will # use if not designated in their block #--------------------------------------------------------------------- defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000 listen stats :81 mode http log global maxconn 10 stats enable stats refresh 30s stats uri /haproxy.stats #--------------------------------------------------------------------- # main frontend which proxys to the backends #--------------------------------------------------------------------- frontend main *:80 default_backend httpd #--------------------------------------------------------------------- # round robin balancing between the various backends #--------------------------------------------------------------------- backend httpd balance roundrobin server haproxy01 192.168.110.131:85 check server haproxy02 192.168.110.132:85 check |
ㅁ haproxy 로그 설정
rsyslog 에 haproxy 용 로그를 남기도록 설정한다. /etc/rsyslog.d/haproxy.conf 파일을 다음과 같이 구성한다.
| [root@haproxy01 haproxy]# cat /etc/rsyslog.d/haproxy.conf # Provides UDP syslog reception $ModLoad imudp $UDPServerRun 514 $AllowedSender UDP, 127.0.0.1 $template Haproxy, "%msg%\n" #rsyslog 에는 rsyslog 가 메세지를 수신한 시각 및 데몬 이름같은 추가적인 정보가 prepend 되므로, message만 출력하는 템플릿 지정 # 이를 haproxy-info.log에만 적용한다. # 모든 haproxy를 남기려면 다음을 주석 해제, 단 access log가 기록되므로, 양이 많다. #local2.* /var/log/haproxy/haproxy.log # local2.info는 haproxy 에서 에러로 처리된 이벤트들만 기록하게 됨 (포맷 적용) local2.info /var/log/haproxy/haproxy-info.log;Haproxy # local0.notice는 haproxy 가 재시작되는 경우와 같은 시스템 메세지를 기록하게됨 (포맷 미적용) local2.notice /var/log/haproxy/haproxy-notice.log |
logroate에 haproxy 설정을 추가한다. /etc/logrotate.d/haproxy 파일을 다음과 같이 구성한다. haproxy 는 재시작할 필요가 없으므로 rsyslog를 재시작해준다.
| [root@haproxy01 haproxy]# cat /etc/logrotate.d/haproxy /var/log/haproxy/*.log { daily rotate 30 create 0644 nobody nobody missingok notifempty compress sharedscripts postrotate /bin/systemctl restart rsyslog.service > /dev/null 2>/dev/null || true # /bin/kill -HUP `cat /var/run/syslogd.pid 2> /dev/null` 2> /dev/null || true # /bin/kill -HUP `cat /var/run/rsyslogd.pid 2> /dev/null` 2> /dev/null || true endscript } [root@haproxy01 haproxy]# systemctl restart rsyslog [root@haproxy01 haproxy]# systemctl status rsyslog ● rsyslog.service - System Logging Service Loaded: loaded (/usr/lib/systemd/system/rsyslog.service; enabled; vendor preset: enabled) Active: active (running) since Sun 2019-08-25 12:31:53 KST; 13min ago Docs: man:rsyslogd(8) http://www.rsyslog.com/doc/ Main PID: 1320 (rsyslogd) CGroup: /system.slice/rsyslog.service └─1320 /usr/sbin/rsyslogd -n Aug 25 12:31:53 haproxy01 rsyslogd[1320]: [origin software="rsyslogd" swVersion="8.24.0" x-pid="1320" ...tart Aug 25 12:31:53 haproxy01 systemd[1]: Starting System Logging Service... Aug 25 12:31:53 haproxy01 systemd[1]: Started System Logging Service. [root@haproxy01 haproxy]# ln -s /var/log/haproxy logs [root@haproxy01 haproxy]# ll -rw-r--r-- 1 root root 1973 Aug 25 12:30 haproxy.cfg lrwxrwxrwx 1 root root 16 Aug 25 12:31 logs -> /var/log/haproxy |
Status 확인
브라우저로 http://192.168.110.130:81/haproxy.stats 에 접속해보시면 HAProxy의 현재상황을 확인가능합니다.
| [root@haproxy02 haproxy]# cat haproxy.cfg #--------------------------------------------------------------------- # Global settings #--------------------------------------------------------------------- global log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon # turn on stats unix socket stats socket /var/lib/haproxy/stats #--------------------------------------------------------------------- # common defaults that all the 'listen' and 'backend' sections will # use if not designated in their block #--------------------------------------------------------------------- defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000 listen stats :81 mode http log global maxconn 10 stats enable stats refresh 30s stats uri /haproxy.stats #--------------------------------------------------------------------- # main frontend which proxys to the backends #--------------------------------------------------------------------- frontend main *:80 default_backend httpd #--------------------------------------------------------------------- # round robin balancing between the various backends #--------------------------------------------------------------------- backend httpd balance roundrobin server haproxy01 192.168.110.131:85 check server haproxy02 192.168.110.132:85 check |
| [root@haproxy01 ~]# systemctl stop haproxy [root@haproxy01 ~]# systemctl start haproxy [root@haproxy01 ~]# systemctl status haproxy ● haproxy.service - HAProxy Load Balancer Loaded: loaded (/usr/lib/systemd/system/haproxy.service; disabled; vendor preset: disabled) Active: active (running) since 금 2019-08-23 16:45:05 KST; 4s ago Main PID: 30008 (haproxy-systemd) CGroup: /system.slice/haproxy.service ├─30008 /usr/sbin/haproxy-systemd-wrapper -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid ├─30009 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds └─30010 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds 8월 23 16:45:05 haproxy01 systemd[1]: Started HAProxy Load Balancer. 8월 23 16:45:05 haproxy01 systemd[1]: Starting HAProxy Load Balancer... 8월 23 16:45:05 haproxy01 haproxy-systemd-wrapper[30008]: haproxy-systemd-wrapper: executing /usr/sbin/...-Ds |
| [root@haproxy02 ~]# systemctl stop haproxy [root@haproxy02 ~]# systemctl start haproxy [root@haproxy02 ~]# systemctl status haproxy ● haproxy.service - HAProxy Load Balancer Loaded: loaded (/usr/lib/systemd/system/haproxy.service; disabled; vendor preset: disabled) Active: active (running) since 금 2019-08-23 16:45:41 KST; 5s ago Main PID: 3498 (haproxy-systemd) CGroup: /system.slice/haproxy.service ├─3498 /usr/sbin/haproxy-systemd-wrapper -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid ├─3499 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds └─3500 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds 8월 23 16:45:41 haproxy02 systemd[1]: Started HAProxy Load Balancer. 8월 23 16:45:41 haproxy02 systemd[1]: Starting HAProxy Load Balancer... 8월 23 16:45:41 haproxy02 haproxy-systemd-wrapper[3498]: haproxy-systemd-wrapper: executing /usr/sbin/...-Ds |
ㅁ VIP 및 이중화 테스트
ㅁ was01
| [root@was01 keepalived]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:5f:36:ae brd ff:ff:ff:ff:ff:ff inet 192.168.110.141/24 brd 192.168.110.255 scope global noprefixroute eth0 valid_lft forever preferred_lft forever inet 192.168.110.140/32 scope global eth0 valid_lft forever preferred_lft forever |
[root@was01 keepalived]# systemctl stop keepalived
was01에 140 IP가 failover되어 was02에 올라온다.
ㅁ was02
| [root@was02 keepalived]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:da:1a:0a brd ff:ff:ff:ff:ff:ff inet 192.168.110.142/24 brd 192.168.110.255 scope global noprefixroute eth0 valid_lft forever preferred_lft forever inet 192.168.110.140/32 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::20c:29ff:feda:1a0a/64 scope link valid_lft forever preferred_lft forever |
1. VIP가 올라온 서버의 keepalived가 중지된다면 서비스 정상(failover)
| --haproxy01 장애 상황 [root@haproxy01 ~]# systemctl stop keepalived --haproxy02에 VIP가 올라오며, 서비스 정상 [root@haproxy02 ~]# tail -f /var/log/messages Aug 23 16:56:53 haproxy02 Keepalived_vrrp[3528]: VRRP_Instance(VI_2) Transition to MASTER STATE Aug 23 16:56:54 haproxy02 Keepalived_vrrp[3528]: VRRP_Instance(VI_2) Entering MASTER STATE Aug 23 16:56:54 haproxy02 Keepalived_vrrp[3528]: VRRP_Instance(VI_2) setting protocol VIPs. Aug 23 16:56:54 haproxy02 Keepalived_vrrp[3528]: Sending gratuitous ARP on eth0 for 192.168.110.140 Aug 23 16:56:54 haproxy02 Keepalived_vrrp[3528]: VRRP_Instance(VI_2) Sending/queueing gratuitous ARPs on eth0 for 192.168.110.140 Aug 23 16:56:54 haproxy02 Keepalived_vrrp[3528]: Sending gratuitous ARP on eth0 for 192.168.110.140 |
이유 : VIP는 haproxy01에 올라와 있지만,
haproxy가 죽어서 80포트로 haproxy01:85, haproxy02:85로 httpd 서비스를 로드밸런싱을 할 수 없으므로 장애 발생
| [root@haproxy01 ~]# systemctl stop haproxy |
1. HAproxy 가 설치된 서버의 커널 값을 수정합니다. (두 대 모두 수행)
| # vi /etc/sysctl.conf net.ipv4.ip_nonlocal_bind=1 |
위 부분이 중요한 부분인데, 위 옵션이 뭔지 찾아보면
로컬 IP가 아닌 주소에 bind() 할 수 있게 해줍니다. 라고 되어 있는데요. 말이 어려운데요.
다시 말해서 현재 가지고 있는 IP가 아닌 다른 외부 IP를 NIC에 바인딩 할 수 있게 해준다는 뜻입니다.
이게 왜 중요하냐면 서비스인 VIP를 첫번째 서버가 가지고 있다가 장애가 나는 경우
Standby 서버로 그 VIP를 옮겨야 서비스가 끊기지 않고 돌아갈 수 있기 때문이죠.
저 옵션이 되어 있지 않은 경우 VIP를 바인딩 할 수 없기 때문에 꼭 수정해줘야 합니다.
2. 커널 값 적용 및 확인 (두 대 모두 수행)
| # sysctl -p # cat /proc/sys/net/ipv4/ip_nonlocal_bind 1 |
위 처럼 1이 나오면 정상적으로 적용됨.
안되는 경우 reboot
출처: https://livegs.tistory.com/44 [if (feel)]
[실무] keepalived.conf 비교
| haproxy1 | haproxy2 |
| [sshan@haproxy1 keepalived]$ cat keepalived.conf ! Configuration File for keepalived global_defs { router_id HAProxy1 } vrrp_script haproxy { script "killall -0 haproxy" interval 2 weight 2 } vrrp_instance VI_1 { debug 2 virtual_router_id 50 advert_int 1 priority 101 state MASTER interface eth0 unicast_src_ip 192.168.110.152 unicast_peer { 192.168.110.153 } virtual_ipaddress { 192.168.110.154 dev eth0 } track_script { haproxy } notify_master "/etc/keepalived/master.sh" notify_backup "/etc/keepalived/backup.sh" } [sshan@haproxy1 keepalived]$ cat master.sh DATE=`date +%Y%m%d` TIME=`date +%Y%m%d_%H%M%S` echo "[$TIME] [HAProxy MASTER] ACTIVE" >> /etc/keepalived/log_$DATE.log curl -d "message=[HAProxy MASTER] ACTIVE" http://192.168.110.119:9201/sendMessage [sshan@haproxy1 keepalived]$ cat backup.sh DATE=`date +%Y%m%d` TIME=`date +%Y%m%d_%H%M%S` echo "[$TIME] [HAProxy MASTER] ERROR - Changed SALVE(STAND BY)" >> /etc/keepalived/log_$DATE.log curl -d "message=[HAProxy MASTER] ERROR - Changed SALVE(STAND BY)" http://192.168.110.119:9201/sendMessage | [sshan@haproxy2 keepalived]$ cat keepalived.conf ! Configuration File for keepalived global_defs { router_id HAProxy2 } vrrp_script haproxy { script "killall -0 haproxy" interval 2 weight 2 } vrrp_instance VI_1 { debug 2 virtual_router_id 50 advert_int 1 priority 100 state BACKUP interface eth0 unicast_src_ip 192.168.110.153 unicast_peer { 192.168.110.152 } virtual_ipaddress { 192.168.110.154 dev eth0 } track_script { haproxy } notify_master "/etc/keepalived/master.sh" notify_backup "/etc/keepalived/backup.sh" } [sshan@haproxy2 keepalived]$ cat master.sh DATE=`date +%Y%m%d` TIME=`date +%Y%m%d_%H%M%S` echo "[$TIME] [HAProxy SALVE] STAND BY ACTIVE" >> /etc/keepalived/log_$DATE.log curl -d "message=[HAProxy SLAVE] STAND BY ACTIVE" http://192.168.110.119:9201/sendMessage [sshan@haproxy2 keepalived]$ cat backup.sh DATE=`date +%Y%m%d` TIME=`date +%Y%m%d_%H%M%S` echo "[$TIME] [HAProxy SLAVE] MASTER RESTORE - Changed MASTER" >> /etc/keepalived/log_$DATE.log curl -d "message=[HAProxy SLAVE] MASTER RESTORE - Changed MASTER" http://192.168.110.119:9201/sendMessage |
ㅁ 실무 설정 예제
| [root@haproxy1 haproxy]# cat haproxy.cfg #--------------------------------------------------------------------- # Global settings #--------------------------------------------------------------------- global # to have these messages end up in /var/log/haproxy.log you will # need to: # # 1) configure syslog to accept network log events. This is done # by adding the '-r' option to the SYSLOGD_OPTIONS in # /etc/sysconfig/syslog # # 2) configure local2 events to go to the /var/log/haproxy.log # file. A line like the following can be added to # /etc/sysconfig/syslog # # local2.* /var/log/haproxy.log # log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon # turn on stats unix socket stats socket /var/lib/haproxy/stats #--------------------------------------------------------------------- # common defaults that all the 'listen' and 'backend' sections will # use if not designated in their block #--------------------------------------------------------------------- defaults mode http #log global #option httplog option dontlognull option http-server-close #option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s #timeout client 1m timeout client 5000 timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000 # id # 101 ~ 200 = HTTP # 201 ~ 300 = TCP # 501 ~ 600 = TEST frontend searchWas bind 192.168.xxx.154:80 option httplog log 127.0.0.1 local3 default_backend searchWas backend searchWas id 101 stats enable stats hide-version balance roundrobin # For Sticky Session appsession JSESSIONID len 30 timeout 3h request-learn prefix option httplog log 127.0.0.1 local3 option httpchk GET /info.jsp option http-server-close option forwardfor server search11 192.168.xxx.61:8280 maxconn 3000 check inter 5000 fastinter 1000 rise 3 fall 1 server search12 192.168.xxx.62:8280 maxconn 3000 check inter 5000 fastinter 1000 rise 3 fall 1 server search21 192.168.xxx.101:8280 maxconn 3000 check inter 5000 fastinter 1000 rise 3 fall 1 server search22 192.168.xxx.102:8280 maxconn 3000 check inter 5000 fastinter 1000 rise 3 fall 1 listen aqmp 192.168.xxx.154:5672 id 201 mode tcp balance roundrobin #timeout client 3h #timeout server 3h option tcplog log 127.0.0.1 local5 option clitcpka server mq11 192.168.xxx.146:5672 check inter 5s rise 2 fall 3 server mq21 192.168.xxx.147:5672 check inter 5s rise 2 fall 3 listen konanSearch5 192.168.xxx.154:7577 id 202 mode tcp balance roundrobin #timeout client 3h #timeout server 3h option tcplog log 127.0.0.1 local4 option clitcpka server nsearch01 192.168.xxx.103:7577 maxconn 3000 check inter 5s rise 2 fall 3 server nsearch02 192.168.xxx.104:7577 maxconn 3000 check inter 5s rise 2 fall 3 server nsearch03 192.168.xxx.106:7577 maxconn 3000 check inter 5s rise 2 fall 3 server nsearch04 192.168.xxx.107:7577 maxconn 3000 check inter 5s rise 2 fall 3 listen searchDocruzer 192.168.xxx.154:8577 id 203 mode tcp balance roundrobin #timeout client 3h #timeout server 3h option tcplog log 127.0.0.1 local4 option clitcpka server nsearch01 192.168.xxx.103:8577 maxconn 3000 check inter 5s rise 2 fall 3 server nsearch02 192.168.xxx.104:8577 maxconn 3000 check inter 5s rise 2 fall 3 server nsearch03 192.168.xxx.106:8577 maxconn 3000 check inter 5s rise 2 fall 3 server nsearch04 192.168.xxx.107:8577 maxconn 3000 check inter 5s rise 2 fall 3 listen ktdev 192.168.xxx.154:22000 id 551 mode http balance roundrobin #timeout client 3h #timeout server 3h option tcplog log 127.0.0.1 local2 option clitcpka # server dev 10.65.141.66:22000 maxconn 3000 check inter 5s rise 2 fall 3 server dev1 10.62.23.40:22000 maxconn 3000 check inter 5s rise 2 fall 3 listen ktstage 192.168.xxx.154:23000 id 552 mode http balance roundrobin #timeout client 3h #timeout server 3h option tcplog log 127.0.0.1 local2 option clitcpka server stage 10.62.5.113:23000 maxconn 3000 check inter 5s rise 2 fall 3 server dev2 10.62.23.40:23000 maxconn 3000 check inter 5s rise 2 fall 3 listen ktlive 192.168.xxx.154:24000 id 553 mode http balance roundrobin #timeout client 3h #timeout server 3h option tcplog log 127.0.0.1 local2 option clitcpka server live 10.65.141.236:24000 maxconn 3000 check inter 5s rise 2 fall 3 listen stats 0.0.0.0:8080 #Listen on all IP's on port 9000 mode http balance timeout client 5000 timeout connect 4000 timeout server 30000 #This is the virtual URL to access the stats page stats uri /haproxy_stats #Authentication realm. This can be set to anything. Escape space characters with a backslash. stats realm HAProxy\ Statistics #The user/pass you want to use. Change this password! #stats auth admin:1230987 #This allows you to take down and bring up back end servers. #This will produce an error on older versions of HAProxy. stats admin if TRUE |
Apache + Tomcat 연동은 아래 게시물을 참고하세요.
Apache2.4 Tomcat8.5 mod_jk 연동 설정 (세션 유지)
https://blog.naver.com/hanajava/221601189158
Keepalived
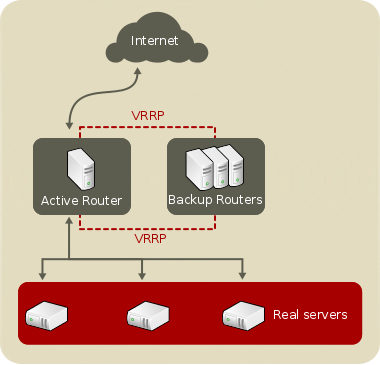
- Routing software
- VRRP 프로토콜을 이용해서 Active-Standby 가능하게 합니다.
( 이미지 출처 : access.redhat.com)
- 사용하는 기능
- High-Availiablility (고가용성) ; VRRP 프로토콜 이용
- < VRRP 란? > - Virtual Router Redundancy Protocol - 하나 이상의 Standby 라우터를 가질 수 있는 방법을 제공하는 인터넷 프로토콜입니다. - VIP(Virtual IP)가 필요합니다. - 각 서버들은 Master, Standby 으로 역할이 나뉘며 Master는 VIP 를 사용합니다. - Health-ckeck를 통해 Master 에게 문제가 발생이 인지되는 경우, Master 서버의 역할이 Standby 서버로 전환됩니다. Standby 서버중 하나의 역할이 Master 로 전환 그리고 VIP를 넘겨받습니다.
- 주의사항
- Active와 stnadby 장비는 인증절차 없이 양방향 ssh접속필요 합니다. (ssh-keygen -t rsa로 구글링)
https://blog.naver.com/PostView.nhn?isHttpsRedirect=true&blogId=hanajava&logNo=221626055915&categoryNo=40&parentCategoryNo=40&viewDate=¤tPage=1&postListTopCurrentPage=1&from=postList
17. InfluxData Support Policies & better utilize InfluxData Support
Health Check
Named Contacts
Your support contract grants elevated priorities to requests from email addresses ending in your domain name. Issues reported from another address may receive slower responses.
License Requirements
InfluxDB Enterprise clusters require a license. To use a license key, all nodes in the cluster must be able to contact https://portal.influxdata.com via port 80 or port 443. If nodes in the cluster cannot communicate with https://portal.influxdata.com, please contact salesops@influxdata.com to request a license file. Information on setting up nodes to use license files and license expiration grace periods can be found here.
If you are unsure which license type you need, please review our license documentation, located here.
InfluxDB Insights
As a best practice for monitoring the health and operations of your InfluxDB cluster, we highly recommend that you take advantage of InfluxDB Insights – a free monitoring service available by our Support team.
We recommend that you get started at influxdbu.com with the following courses:
InfluxData provides documentation for many common issues and use cases. Following documentation will help you get started and answer many of the questions you may have throughout implementation and maintenance of InfluxData Platform.
You may submit support requests (“tickets”) through InfluxData’s support platform (“Support Platform”) by emailing support@influxdata.com, entering a ticket at https://support.influxdata.com, or, for Critical Issues, by opening a case and contacting the InfluxData support team by telephone at the toll-free telephone number. The most updated contact numbers can be found in section 1.6.1 of the Support policy.
InfluxData will keep a record of each ticket within the Support Platform to enable you to see all current tickets, enter new tickets, review historical tickets, and edit or respond to current tickets. InfluxData Support Platform is configured to send email notifications to Customer when a ticket is updated.
All tickets are assigned a ticket number and responded to automatically to confirm receipt of such ticket. All correspondence and telephone calls are logged with a time-stamp for quality assurance.
Severity Level 1 issues should be simultaneously reported by telephone and through the Support Platform. All issues categorized with a severity level other than Severity 1 should be reported through the Support Platform. When reporting an issue, you must specify how the issue is affecting its use of InfluxDB, and provide all information reasonably requested by InfluxData to resolve the issue in a timely manner.
If you are reporting an issue or bug with the system, please provide as much of the following information as practical and relevant. The earlier we have the relevant data, the faster we can diagnose and address the issue.
Please schedule a Health Check with our Customer Success Engineering team. In our Health Check session we will be:
|
Your support contract grants elevated priorities to requests from email addresses ending in your domain name. Issues reported from another address may receive slower responses.
License Requirements
InfluxDB Enterprise clusters require a license. To use a license key, all nodes in the cluster must be able to contact https://portal.influxdata.com via port 80 or port 443. If nodes in the cluster cannot communicate with https://portal.influxdata.com, please contact salesops@influxdata.com to request a license file. Information on setting up nodes to use license files and license expiration grace periods can be found here.
If you are unsure which license type you need, please review our license documentation, located here.
InfluxDB Insights
As a best practice for monitoring the health and operations of your InfluxDB cluster, we highly recommend that you take advantage of InfluxDB Insights – a free monitoring service available by our Support team.
- Reduced operational burden – allow us to configure your external monitoring, and proactively alert you when something looks awry.
- Reduced time to diagnosis – visibility of your system’s health metrics accelerates the investigation and resolution of issues.
- Improved service availability and performance – our team applies the same cluster health metrics received from InfluxDB Insights as are used for monitoring our fully managed InfluxDB Cloud offering.
We recommend that you get started at influxdbu.com with the following courses:
- Installing InfluxDB Enterprise: https://university.influxdata.com/courses/installing-influxdb-enterprise-tutorial/
- Intro to InfluxDB Enterprise: https://university.influxdata.com/courses/intro-to-influxdb-enterprise-tutorial
- Best Practices for Configuring InfluxDB Enterprise: https://university.influxdata.com/courses/configuring-influxdb-enterprise-best-practices-tutorial/
InfluxData provides documentation for many common issues and use cases. Following documentation will help you get started and answer many of the questions you may have throughout implementation and maintenance of InfluxData Platform.
- Support || https://support.influxdata.com/ || support@influxdata.com. If you don’t already have a profile, you may register on our support portal here: https://support.influxdata.com/s/login/SelfRegister
- InfluxDB Enterprise Installation: https://docs.influxdata.com/enterprise_influxdb/latest/introduction/installation/
- Monitoring InfluxData Platform: We highly recommend monitoring your InfluxData Platform. Refer to https://docs.influxdata.com/platform/introduction
- Schema Design: https://docs.influxdata.com/enterprise_influxdb/latest/concepts/schema_and_data_layout/ & https://awesome.influxdata.com/docs/part-2/designing-your-schema/
- Batching Writes: https://docs.influxdata.com/resources/videos/telegraf-agent-config-best-practice/
- API Libraries: https://docs.influxdata.com/enterprise_influxdb/latest/tools/api_client_libraries/
- InfluxData Community Site: Explore, Ask, Learn with your peers at http://community.influxdata.com
- InfluxData Documentation: https://docs.influxdata.com/
You may submit support requests (“tickets”) through InfluxData’s support platform (“Support Platform”) by emailing support@influxdata.com, entering a ticket at https://support.influxdata.com, or, for Critical Issues, by opening a case and contacting the InfluxData support team by telephone at the toll-free telephone number. The most updated contact numbers can be found in section 1.6.1 of the Support policy.
InfluxData will keep a record of each ticket within the Support Platform to enable you to see all current tickets, enter new tickets, review historical tickets, and edit or respond to current tickets. InfluxData Support Platform is configured to send email notifications to Customer when a ticket is updated.
All tickets are assigned a ticket number and responded to automatically to confirm receipt of such ticket. All correspondence and telephone calls are logged with a time-stamp for quality assurance.
Severity Level 1 issues should be simultaneously reported by telephone and through the Support Platform. All issues categorized with a severity level other than Severity 1 should be reported through the Support Platform. When reporting an issue, you must specify how the issue is affecting its use of InfluxDB, and provide all information reasonably requested by InfluxData to resolve the issue in a timely manner.
If you are reporting an issue or bug with the system, please provide as much of the following information as practical and relevant. The earlier we have the relevant data, the faster we can diagnose and address the issue.
- Describe the issue in detail:
- what was the behavior before and how has it changed?
- have there been any recent changes to the system?
- have there been any unreported issues with the system?
- Provide snippets from the InfluxDB log file for the relevant time frame
- Please run the following queries and include their output:
- SHOW STATS
- SHOW DIAGNOSTICS
- If you suspect data loss or have inconsistent query results, please include the output of the following queries:
- SHOW SHARDS
- SHOW SERIES (issued for each affected database)
- influxd-ctl entropy show (issued on a meta node)
- If you are having performance issues or experiencing OOM errors, please include all of the above, and as much of the following as possible:
- curl -o block.txt "http://localhost:8086/debug/pprof/block?debug=1"
- curl -o goroutine.txt "http://localhost:8086/debug/pprof/goroutine?debug=1"
- curl -o heap.txt "http://localhost:8086/debug/pprof/heap?debug=1"
- curl -o vars.txt "http://localhost:8086/debug/vars"
- iostat -xd 1 30 > iostat.txt
18. KILL QUERY
$ influx
Connected to http://localhost:8086 version v1.10.0
InfluxDB shell version: v1.10.0
> SHOW QUERIES
qid node_id tcp_host query database duration status
--- ------- -------- ----- -------- -------- ------
100 4 data3:8088 DROP MEASUREMENT test test 1630u running
> KILL QUERY 100 ON "data3:8088"
or
> KILL QUERY 100
2. In one SSH session run the following command:
$ journalctl -u influxdb -f > $(hostname)-DROP.log
3. In another SSH session run the actual DROP statement, for example:
> DROP MEASUREMENT test
Let it run for ~5 minutes, then Ctrl-C out of the command in step 2.
4. Attach the log file to this case.
Connected to http://localhost:8086 version v1.10.0
InfluxDB shell version: v1.10.0
> SHOW QUERIES
qid node_id tcp_host query database duration status
--- ------- -------- ----- -------- -------- ------
100 4 data3:8088 DROP MEASUREMENT test test 1630u running
> KILL QUERY 100 ON "data3:8088"
or
> KILL QUERY 100
2. In one SSH session run the following command:
$ journalctl -u influxdb -f > $(hostname)-DROP.log
3. In another SSH session run the actual DROP statement, for example:
> DROP MEASUREMENT test
Let it run for ~5 minutes, then Ctrl-C out of the command in step 2.
4. Attach the log file to this case.
19. influxql explain analyze
So you can use the influxql explain analyze sommand to see how much is being used on these queries:
https://docs.influxdata.com/enterprise_influxdb/v1/query_language/spec/#explain-analyze
If it has not been done, setting the query-timeout, log-queries-after and log-timedout-queries will help identify the offending queries:
https://docs.influxdata.com/enterprise_influxdb/v1/administration/configure/config-data-nodes/#query-timeout
https://docs.influxdata.com/enterprise_influxdb/v1/administration/configure/config-data-nodes/#log-queries-after
https://docs.influxdata.com/enterprise_influxdb/v1/administration/configure/config-data-nodes/#log-timedout-queries--false
https://docs.influxdata.com/enterprise_influxdb/v1/query_language/spec/#explain-analyze
If it has not been done, setting the query-timeout, log-queries-after and log-timedout-queries will help identify the offending queries:
https://docs.influxdata.com/enterprise_influxdb/v1/administration/configure/config-data-nodes/#query-timeout
https://docs.influxdata.com/enterprise_influxdb/v1/administration/configure/config-data-nodes/#log-queries-after
https://docs.influxdata.com/enterprise_influxdb/v1/administration/configure/config-data-nodes/#log-timedout-queries--false
20. reindex 절차
data node에서 아래와 같이 실행한다.(동시에 실행할 필요가 없고 순차적으로data node에서 실행하면 됩니다.)
systemctl stop influxdb.service
find /influxdb/ -type d -name "index" -exec ls -lad {} \;
find /influxdb/ -type d -name "_series" -exec ls -lad {} \;
find /influxdb/ -type d -name "index" | xargs rm -rvf
find /influxdb/ -type d -name "_series" | xargs rm -rvf
influx_inspect buildtsi -datadir /influxdb/data/ -waldir /influxdb/wal/
or
influx_inspect buildtsi -datadir /influxdb/data/ -waldir /influxdb/wal/ 2>&1 | tee -a $(hostname)-buildtsi.log
chown -R influxdb:influxdb /influxdb/*
systemctl start influxdb.service
systemctl stop influxdb.service
find /influxdb/ -type d -name "index" -exec ls -lad {} \;
find /influxdb/ -type d -name "_series" -exec ls -lad {} \;
find /influxdb/ -type d -name "index" | xargs rm -rvf
find /influxdb/ -type d -name "_series" | xargs rm -rvf
influx_inspect buildtsi -datadir /influxdb/data/ -waldir /influxdb/wal/
or
influx_inspect buildtsi -datadir /influxdb/data/ -waldir /influxdb/wal/ 2>&1 | tee -a $(hostname)-buildtsi.log
chown -R influxdb:influxdb /influxdb/*
systemctl start influxdb.service
21. Health Check
Please schedule a Health Check with our Customer Success Engineering team. In our Health Check session we will be:
|
Your support contract grants elevated priorities to requests from email addresses ending in your domain name. Issues reported from another address may receive slower responses.
License Requirements
InfluxDB Enterprise clusters require a license. To use a license key, all nodes in the cluster must be able to contact https://portal.influxdata.com via port 80 or port 443. If nodes in the cluster cannot communicate with https://portal.influxdata.com, please contact salesops@influxdata.com to request a license file. Information on setting up nodes to use license files and license expiration grace periods can be found here.
If you are unsure which license type you need, please review our license documentation, located here.
InfluxDB Insights
As a best practice for monitoring the health and operations of your InfluxDB cluster, we highly recommend that you take advantage of InfluxDB Insights – a free monitoring service available by our Support team.
- Reduced operational burden – allow us to configure your external monitoring, and proactively alert you when something looks awry.
- Reduced time to diagnosis – visibility of your system’s health metrics accelerates the investigation and resolution of issues.
- Improved service availability and performance – our team applies the same cluster health metrics received from InfluxDB Insights as are used for monitoring our fully managed InfluxDB Cloud offering.
We recommend that you get started at influxdbu.com with the following courses:
- Installing InfluxDB Enterprise: https://university.influxdata.com/courses/installing-influxdb-enterprise-tutorial/
- Intro to InfluxDB Enterprise: https://university.influxdata.com/courses/intro-to-influxdb-enterprise-tutorial
- Best Practices for Configuring InfluxDB Enterprise: https://university.influxdata.com/courses/configuring-influxdb-enterprise-best-practices-tutorial/
InfluxData provides documentation for many common issues and use cases. Following documentation will help you get started and answer many of the questions you may have throughout implementation and maintenance of InfluxData Platform.
- Support || https://support.influxdata.com/ || support@influxdata.com. If you don’t already have a profile, you may register on our support portal here: https://support.influxdata.com/s/login/SelfRegister
- InfluxDB Enterprise Installation: https://docs.influxdata.com/enterprise_influxdb/latest/introduction/installation/
- Monitoring InfluxData Platform: We highly recommend monitoring your InfluxData Platform. Refer to https://docs.influxdata.com/platform/introduction
- Schema Design: https://docs.influxdata.com/enterprise_influxdb/latest/concepts/schema_and_data_layout/ & https://awesome.influxdata.com/docs/part-2/designing-your-schema/
- Batching Writes: https://docs.influxdata.com/resources/videos/telegraf-agent-config-best-practice/
- API Libraries: https://docs.influxdata.com/enterprise_influxdb/latest/tools/api_client_libraries/
- InfluxData Community Site: Explore, Ask, Learn with your peers at http://community.influxdata.com
- InfluxData Documentation: https://docs.influxdata.com/
You may submit support requests (“tickets”) through InfluxData’s support platform (“Support Platform”) by emailing support@influxdata.com, entering a ticket at https://support.influxdata.com, or, for Critical Issues, by opening a case and contacting the InfluxData support team by telephone at the toll-free telephone number. The most updated contact numbers can be found in section 1.6.1 of the Support policy.
InfluxData will keep a record of each ticket within the Support Platform to enable you to see all current tickets, enter new tickets, review historical tickets, and edit or respond to current tickets. InfluxData Support Platform is configured to send email notifications to Customer when a ticket is updated.
All tickets are assigned a ticket number and responded to automatically to confirm receipt of such ticket. All correspondence and telephone calls are logged with a time-stamp for quality assurance.
Severity Level 1 issues should be simultaneously reported by telephone and through the Support Platform. All issues categorized with a severity level other than Severity 1 should be reported through the Support Platform. When reporting an issue, you must specify how the issue is affecting its use of InfluxDB, and provide all information reasonably requested by InfluxData to resolve the issue in a timely manner.
If you are reporting an issue or bug with the system, please provide as much of the following information as practical and relevant. The earlier we have the relevant data, the faster we can diagnose and address the issue.
- Describe the issue in detail:
- what was the behavior before and how has it changed?
- have there been any recent changes to the system?
- have there been any unreported issues with the system?
- Provide snippets from the InfluxDB log file for the relevant time frame
- Please run the following queries and include their output:
- SHOW STATS
- SHOW DIAGNOSTICS
- If you suspect data loss or have inconsistent query results, please include the output of the following queries:
- SHOW SHARDS
- SHOW SERIES (issued for each affected database)
- influxd-ctl entropy show (issued on a meta node)
- If you are having performance issues or experiencing OOM errors, please include all of the above, and as much of the following as possible:
- curl -o block.txt "http://localhost:8086/debug/pprof/block?debug=1"
- curl -o goroutine.txt "http://localhost:8086/debug/pprof/goroutine?debug=1"
- curl -o heap.txt "http://localhost:8086/debug/pprof/heap?debug=1"
- curl -o vars.txt "http://localhost:8086/debug/vars"
- iostat -xd 1 30 > iostat.txt
22. compactions disabled
Prior to upgrading this cluster, please confirm the current thingworx version to ensure compatibility.
Also, the "compactions disabled" error indicates that a shard is not being fully compacted (likely because it is a "hot shard"). Are you backfilling or writing any historical data? If so, this could be causing the errors.
Run the following on each data node but update /var/influxdb/data to point to the data directories of your data nodes:
find /var/influxdb/data -type d -mindepth 3 -maxdepth 3 -exec du -sh {} \;
이 클러스터를 업그레이드하기 전에 현재 thingworx 버전을 확인하여 호환성을 확인하세요.
또한 "압축 비활성화됨" 오류는 샤드가 완전히 압축되지 않았음을 나타냅니다(아마도 "핫 샤드"이기 때문일 수 있음). 과거 데이터를 채우거나 기록하고 있나요? 그렇다면 이로 인해 오류가 발생할 수 있습니다.
각 데이터 노드에서 다음을 실행하되 데이터 노드의 데이터 디렉터리를 가리키도록 /var/influxdb/data를 업데이트합니다.
/var/influxdb/data -type d -minlength 3 -maxlength 3 -exec du -sh {} \를 찾으세요.
==========
I noticed actually that the shards you copied between systems are staying as hot, despite having not been written to for a number of days. This will mean they are not being compacted correctly. The least intrusive way to try to move these along in the short term would be to run a influxd-ctl truncate shards on a meta node, which will close all active shards and create new ones. Whilst this in principle does not relate to your older shards which are actively NOT being written to, it will still potentially follow the same logic that is leaving them marked as hot, and may clear something down in the process.
So run
influxd-ctl truncate shards
and then after at least 4 hours has passed, do a
influxd-ctl show-shards -v
To see if shards 534, 568, 600 and 632 are still being marked as hot. If you can send us this output and the logfile during that time span, that would be very useful.
If this does not have a notable impact then we might want to look at performing the copy-shard operation on those shards again, but back in the opposite direction. On disk they appear to have the exact same size, so contain the same data, but at some point from them being loaded by influxdb, they take a different value. Sending the data back to where it came from should iron out any small differences in the older source data and the recently copied version.
Note that shard 534 is due to expire in 12 days time anyway due to the retention policy, so hopefully there is little concern about data security if there was any, as that shard is soon to be fully deleted.
Also, the "compactions disabled" error indicates that a shard is not being fully compacted (likely because it is a "hot shard"). Are you backfilling or writing any historical data? If so, this could be causing the errors.
Run the following on each data node but update /var/influxdb/data to point to the data directories of your data nodes:
find /var/influxdb/data -type d -mindepth 3 -maxdepth 3 -exec du -sh {} \;
이 클러스터를 업그레이드하기 전에 현재 thingworx 버전을 확인하여 호환성을 확인하세요.
또한 "압축 비활성화됨" 오류는 샤드가 완전히 압축되지 않았음을 나타냅니다(아마도 "핫 샤드"이기 때문일 수 있음). 과거 데이터를 채우거나 기록하고 있나요? 그렇다면 이로 인해 오류가 발생할 수 있습니다.
각 데이터 노드에서 다음을 실행하되 데이터 노드의 데이터 디렉터리를 가리키도록 /var/influxdb/data를 업데이트합니다.
/var/influxdb/data -type d -minlength 3 -maxlength 3 -exec du -sh {} \를 찾으세요.
==========
I noticed actually that the shards you copied between systems are staying as hot, despite having not been written to for a number of days. This will mean they are not being compacted correctly. The least intrusive way to try to move these along in the short term would be to run a influxd-ctl truncate shards on a meta node, which will close all active shards and create new ones. Whilst this in principle does not relate to your older shards which are actively NOT being written to, it will still potentially follow the same logic that is leaving them marked as hot, and may clear something down in the process.
So run
influxd-ctl truncate shards
and then after at least 4 hours has passed, do a
influxd-ctl show-shards -v
To see if shards 534, 568, 600 and 632 are still being marked as hot. If you can send us this output and the logfile during that time span, that would be very useful.
If this does not have a notable impact then we might want to look at performing the copy-shard operation on those shards again, but back in the opposite direction. On disk they appear to have the exact same size, so contain the same data, but at some point from them being loaded by influxdb, they take a different value. Sending the data back to where it came from should iron out any small differences in the older source data and the recently copied version.
Note that shard 534 is due to expire in 12 days time anyway due to the retention policy, so hopefully there is little concern about data security if there was any, as that shard is soon to be fully deleted.
23. InfluxDB CQ ( continuous query )
Continuous Query
InfluxDB에서 제공하는 CQ ( contiunuous query )는
실시간 데이터 상에서 설정해논 주기대로 자동으로 실행되고 쿼리 결과를 지정한 measurements에 저장하는 " 지속적으로 실행되는 쿼리 " 입니다.
기본 구문
CREATE CONTINUOUS QUERY <cq_name> ON <database_name>
BEGIN <cq_query>
END
▶ cq name : 설정할 CQ를 명시적으로 선언하기 위해 설정하는 이름
▶ database_name : CQ가 어떤 database에서 실행될지 설정
▶ cq_query : 실행시킬 CQ의 본문
CQ_query의 기본 구문
SELECT <function[s]> INTO <destination_measurement> FROM <measurement> [WHERE <stuff>] GROUP BY time(<interval>)[,<tag_key[s]>]
CQ_query의 특징
시스템에 적용하기
현재 센서 데이터 대시보드를 위해서 우리가 원하는 요구사항은 다음과 같다.
[1] Database & measurements 구축
현재 Daq ( 센서 데이터 출력 ) 에서 값들이 초마다 influxDB가 위치한 Port로 넘어오는 환경을 구축해두었습니다.
InfluxDB에서 제공하는 CQ ( contiunuous query )는
실시간 데이터 상에서 설정해논 주기대로 자동으로 실행되고 쿼리 결과를 지정한 measurements에 저장하는 " 지속적으로 실행되는 쿼리 " 입니다.
기본 구문
CREATE CONTINUOUS QUERY <cq_name> ON <database_name>
BEGIN <cq_query>
END
▶ cq name : 설정할 CQ를 명시적으로 선언하기 위해 설정하는 이름
▶ database_name : CQ가 어떤 database에서 실행될지 설정
▶ cq_query : 실행시킬 CQ의 본문
CQ_query의 기본 구문
SELECT <function[s]> INTO <destination_measurement> FROM <measurement> [WHERE <stuff>] GROUP BY time(<interval>)[,<tag_key[s]>]
CQ_query의 특징
- INTO GROUP BY time() 이 필수적으로 필요하다. ( 어떤 시간 간격으로 쿼리가 실행될지 명시해야만 하기 때문에 )
- CQ_query 내에서는 where절로 시간 범위를 설정해도 무시당한다.
- 왜냐하면 CQ_query에서는 CQ를 실행할 때의 시간 범위를 자동으로 생성하기 때문이다.
시스템에 적용하기
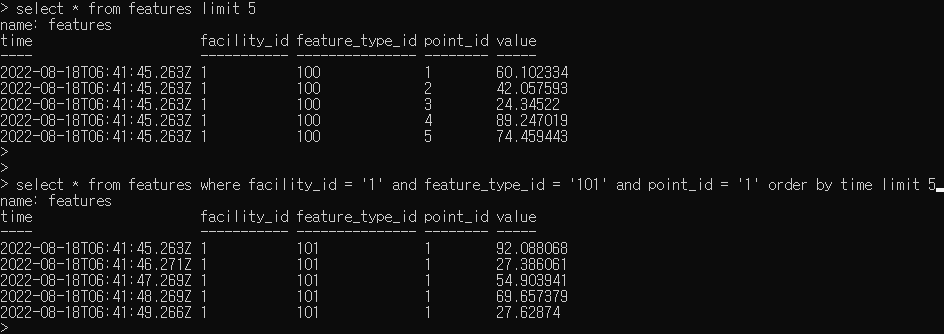
현재 센서 데이터 대시보드를 위해서 우리가 원하는 요구사항은 다음과 같다.
- 매 초마다 각 각의 facility, point, feature_type로 구분되어진 200개의 센서 데이터를 입력받는다.
- 대시보드에는 8개의 센서 값 모니터링 그래프가 구축된다. ( 1H 4H 12H 24H 3D 7D 30D 3M )
- 각 버튼을 누르면 그래프가 그려지고, 각 그래프에서는 3600개의 데이터를 그린다.
- 4H의 경우에는 4초마다 MAX sampling된 value를 출략한다.
- 3D의 경우에는 12분마다 MAX sampling된 value를 출략한다.
- 10분 주기로 max sampling된 데이터를 기록하여 영구적으로 저장한다.
[1] Database & measurements 구축
현재 Daq ( 센서 데이터 출력 ) 에서 값들이 초마다 influxDB가 위치한 Port로 넘어오는 환경을 구축해두었습니다.